RDMA介绍
RDMA优势

- SOCKET: 通过网卡中断通知,在协议栈实现封包解包,需要内存拷贝才能到达用户空间
- DPDK: 通过cpu轮询获知报文到达,将协议栈上移到用户空间,报文由网卡直接DMA到用户空间,虽然实现了零拷贝,但仍然需要cpu做封包解包
- RDMA: 将协议栈下移到网卡,内核bypass,零拷贝,低cpu消耗等
RDMA标准
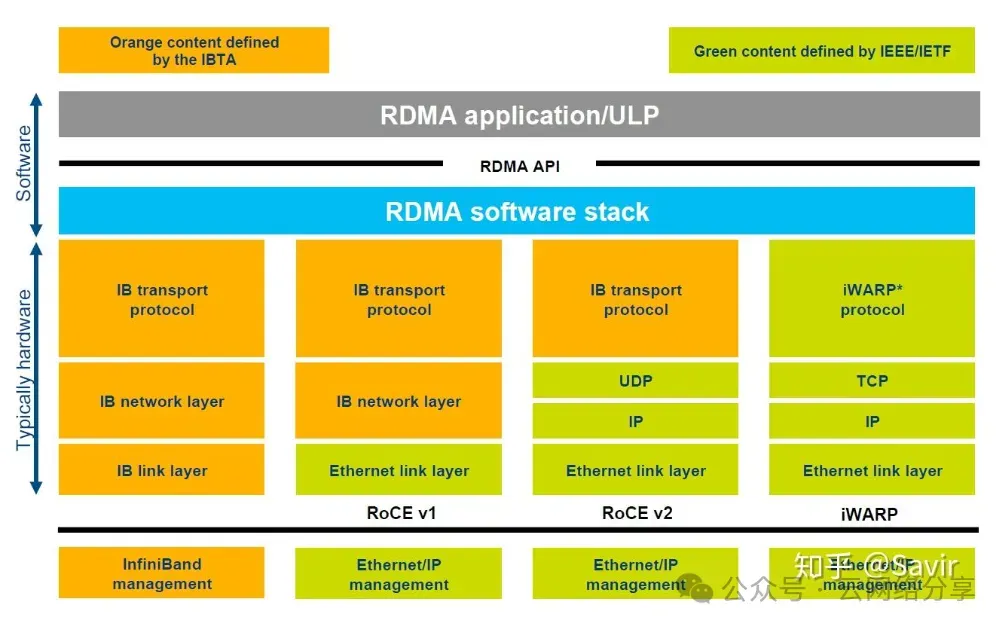
RDMA标准有三种协议实现:IB, ROCE, IWARP
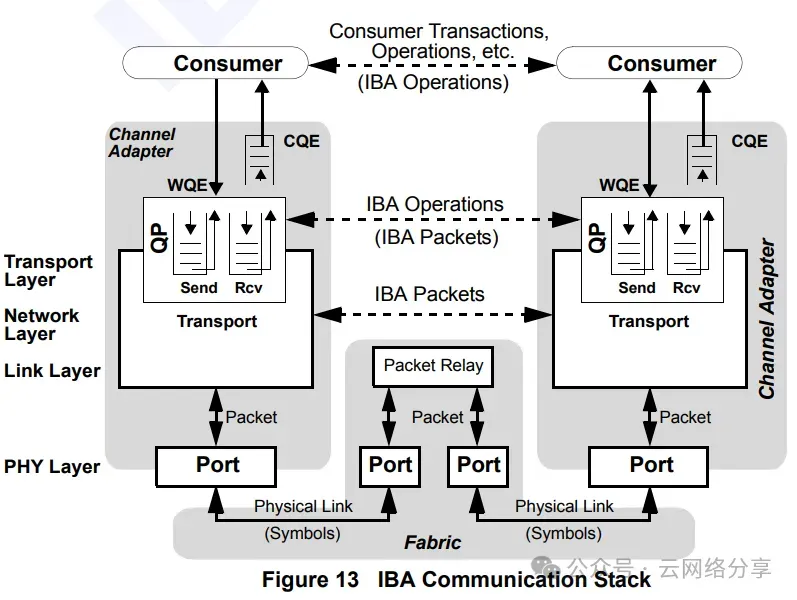
RDMA基本概念
- WQ: work queue,工作队列,应用程序是生成者,网卡是消费者
- WQE: work queue elment,工作队列元素
- QP: queue pair, 队列对,包括SQ和RQ
- SQ: receive queue, 发送队列,属于WQ
- RQ: receive queue, 接收队列,属于WQ
- CQ: completion queue, 完成队列,网卡是生产者,应用程序是消费者
- CQE: completion queue element, 完成队列元素
- WR: work request,工作请求,ibvers api中的参数类型,最终会转换成WQE
- WC: work completion, 工作完成,ibvers api中的参数类型,保存CQE信息
RDMA操作类型
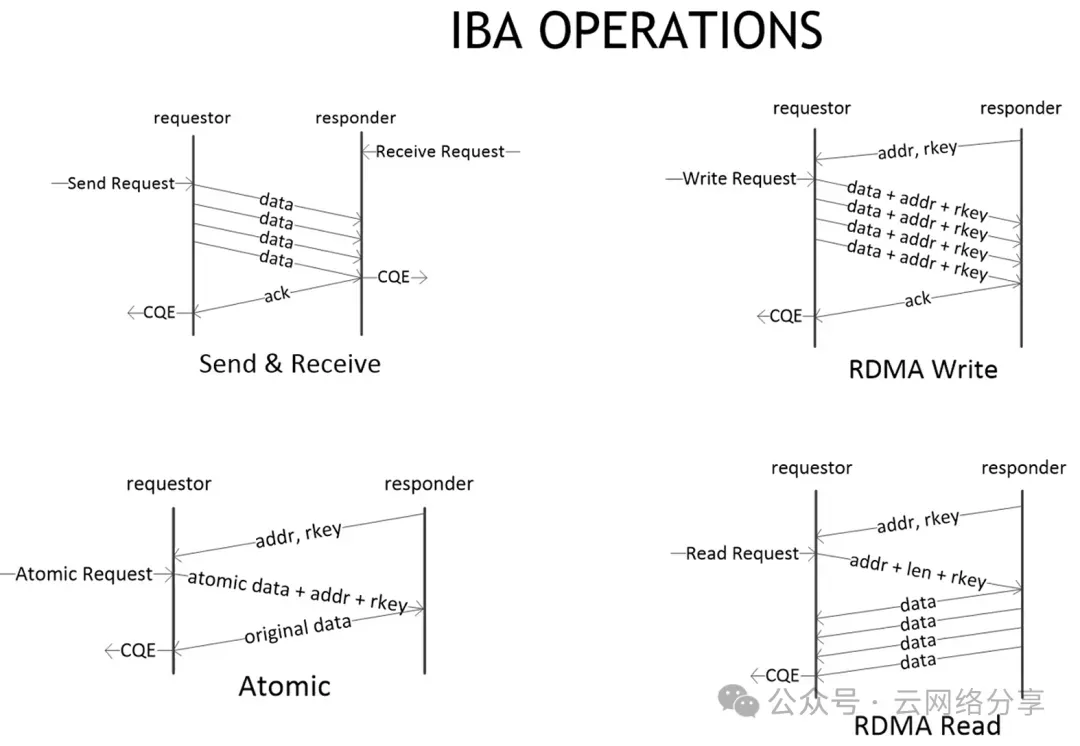
send/recv双端操作(通信需两端cpu参与)
send端需指定本端buffer地址和lkey,网卡从此buffer读取数据封装后发送。不用指定远端buffer信息。
struct ibv_sge sg;
struct ibv_send_wr wr;
struct ibv_send_wr *bad_wr;
memset(&sg, 0, sizeof(sg));
sg.addr = (uintptr_t)buf_addr;
sg.length = buf_size;
sg.lkey = mr->lkey;
memset(&wr, 0, sizeof(wr));
wr.wr_id = 0;
wr.sg_list = &sg;
wr.num_sge = 1;
wr.opcode = IBV_WR_SEND;
wr.send_flags = IBV_SEND_SIGNALED;
if (ibv_post_send(qp, &wr, &bad_wr)) {
fprintf(stderr, "Error, ibv_post_send() failed\n");
return -1;
}recv端指定本端buffer地址和lkey,网卡将报文写到此buffer
struct ibv_sge sg;
struct ibv_recv_wr wr;
struct ibv_recv_wr *bad_wr;
memset(&sg, 0, sizeof(sg));
sg.addr = (uintptr_t)buf_addr;
sg.length = buf_size;
sg.lkey = mr->lkey;
memset(&wr, 0, sizeof(wr));
wr.wr_id = 0;
wr.sg_list = &sg;
wr.num_sge = 1;
if (ibv_post_recv(qp, &wr, &bad_wr)) {
fprintf(stderr, "Error, ibv_post_recv() failed\n");
return -1;
}send端和recv端都会生成CQE
write/read/atomic单端操作(通信不需要远端cpu参与)
不仅需指定本端buffer地址和lkey,也要指定远端buffer地址和rkey。
struct ibv_sge sg;
struct ibv_send_wr wr;
struct ibv_send_wr *bad_wr;
memset(&sg, 0, sizeof(sg));
sg.addr = (uintptr_t)buf_addr; //本端地址,长度和key
sg.length = buf_size;
sg.lkey = mr->lkey;
memset(&wr, 0, sizeof(wr));
wr.wr_id = 0;
wr.sg_list = &sg;
wr.num_sge = 1;
wr.opcode = IBV_WR_RDMA_WRITE;
wr.send_flags = IBV_SEND_SIGNALED;
wr.wr.rdma.remote_addr = remote_address; //远端地址和key,需预先通过别的方式获取
wr.wr.rdma.rkey = remote_key;
if (ibv_post_send(qp, &wr, &bad_wr)) {
fprintf(stderr, "Error, ibv_post_send() failed\n");
return -1;
}只有发送端会生成CQE,通信前需通过socket或者CM获取接收端buffer虚拟地址和rkey,通信后需告知接收端数据已发送
RDMA服务类型
根据可靠性,是否面向连接分为如下几种服务类型

- 可靠: 应答机制,数据校验和保序机制
- 面向连接: 每个QP在初始化时就和目的QP建立关联则称为连接,每个QP发送数据时才指定目的QP则称为数据报
RDMA MR注册
用户空间申请buffer后需要将对应的内存进行注册,注册MR的作用:
- 创建VA到PA的映射表,不管读本端数据还是远端网卡将数据写到远端,网卡都需要根据VA找到对应的PA
- 控制访问权限,注册时会生成lkey和rkey,控制本端和远端访问内存权限
- 避免换页,防止VA到PA映射关系变化
RDMA建连
面向连接的服务类型需要在本端和远端QP之间建立连接后才能通过RDMA进行数据交换,建连需要交换如下信息
- GID: global identifier, 每个网卡的全局唯一标识 (通过命令show_gids查看)
- QPN: queue paire number, 每个qp标识
- VA: virtual address,远端虚拟地址
- RKEY: remote key,远端虚拟地址的key
- PSN: packet sequence number, 初始序列号,接收端根据PSN判断是否乱序
建连两种方式
- 基于socket的带外建连方式。NCCL使用此方式
- 基于CM的带内建连方式,使用QP 1交互,有专属的报文格式,交互流程和用户接口
RDMA API
支持librdmacm和libibvers两种api,这里以libibvers api为例
控制面api(需陷入内核态执行)
获取RDMA设备列表: ibv_get_device_list
打开指定的RDMA设备: ibv_open_device
查询RDMA设备属性: ibv_query_device
申请pd: ibv_alloc_pd
注册MR: ibv_reg_mr
创建CQ: ibv_create_cq
创建QP: ibv_create_qp
修改QP属性: ibv_modify_qp
数据面api(不需要陷入内核态执行)
- 下发发送端wr(异步): int ibv_post_send(struct ibv_qp *qp, struct ibv_send_wr *wr, struct ibv_send_wr **bad_wr)
如何知道下发的wr已完成?
如果通过ibv_modify_qp修改qp时ibv_qp_init_attr.sq_sig_all设置为1,则每个wr都会生成CQE,如果为0,则根据wr.send_flags决定,如果设置了IBV_SEND_SIGNALED则此wr生成CQE,最后通过ibv_poll_cq获取CQE,CQE中包含wr完成情况
- 下发接收端recv wr(异步): int ibv_post_recv(struct ibv_qp *qp, struct ibv_recv_wr *wr, struct ibv_recv_wr **bad_wr)
struct ibv_recv_wr {
uint64_t wr_id;
struct ibv_recv_wr *next;
struct ibv_sge *sg_list; //指定本端buffer地址
int num_sge;
};如何知道下发的rwr已完成?
发送端发送如下请求时,会触发接收端生成CQE,最后通过ibv_poll_cq获取CQE,CQE中包含rwr完成情况
-
Send
-
Send with Immediate
-
RDMA Write with immediate
-
获取wc: int ibv_poll_cq(struct ibv_cq *cq, int num_entries, struct ibv_wc *wc)
RDMA 传输头
基础传输头
每个roce报文都包含此头部
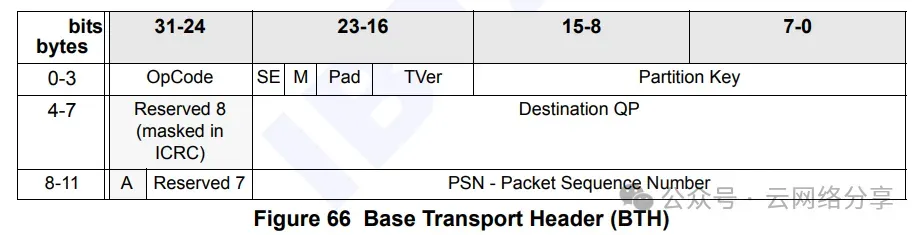
- opcode: 操作类型,write first/write middle/write last/write only等
- destination QP: 目的qpn
- A: ackreq, 是否需要对端回复ack,如果报文分片只有最后一个报文设置为1,中间的报文不需要ack
- PSN: 报文序号,接收端根据PSN判断是否乱序
RETH扩展传输头
指定了远端虚拟地址,key和此报文传输的payload长度。write first/write only类型报文包含此头部

AETH扩展传输头
接收端响应报文,告知发送端数据是否正常
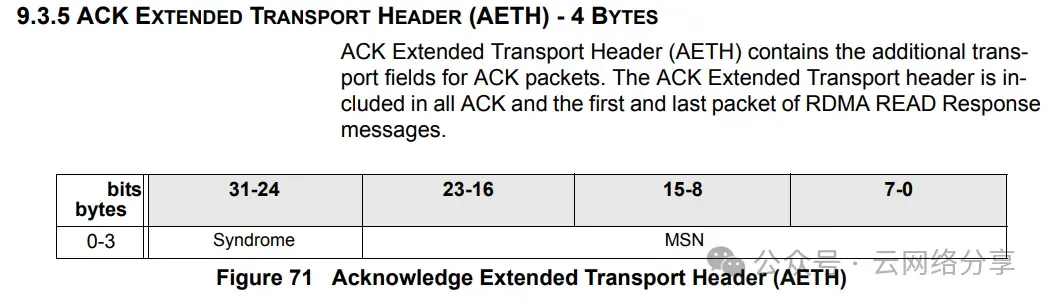
syndrome的bit5:6代表ACK或NAK
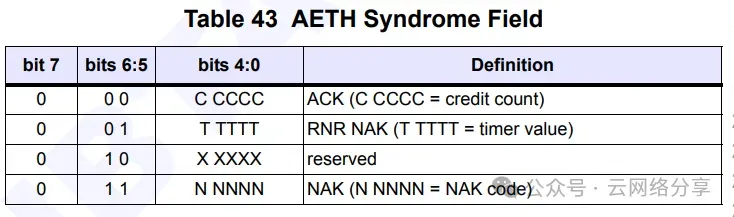
bit5:6为11表示NAK,说明有错误发送,bit4:4标识错误原因
MTU
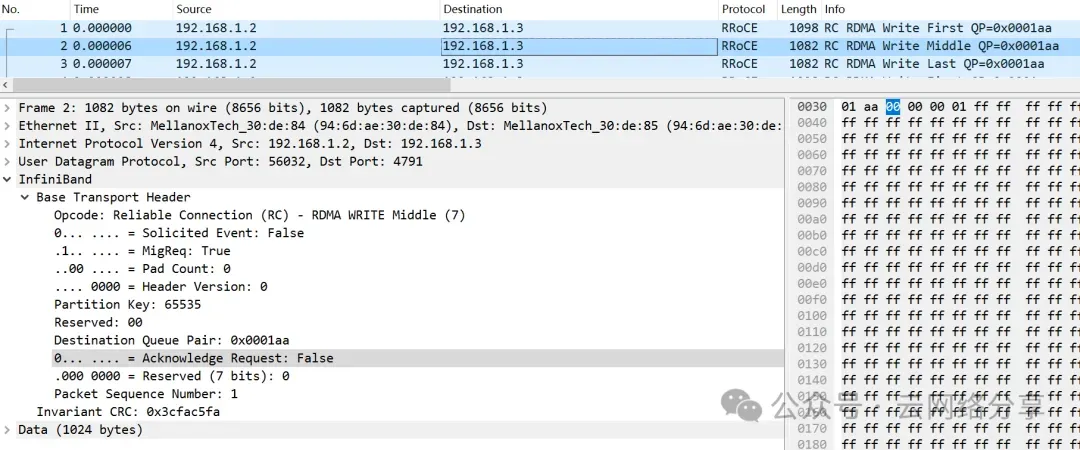
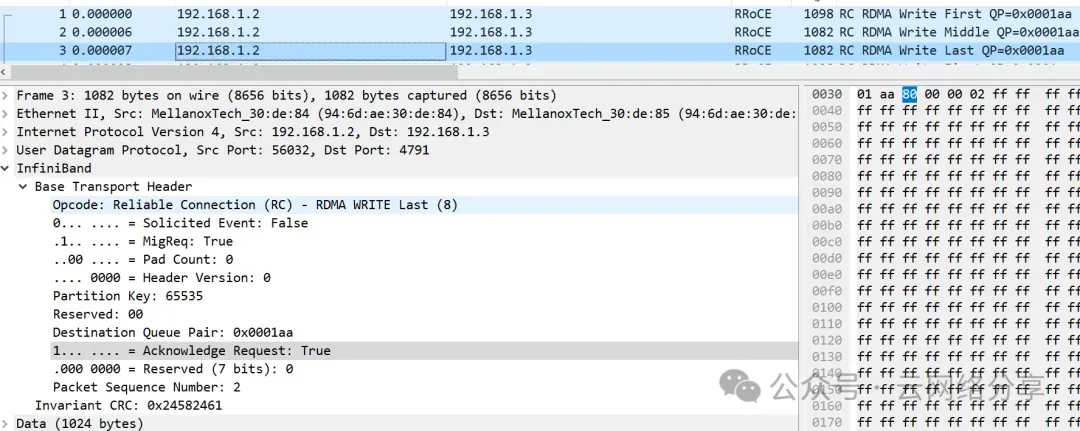
MTU支持设置为256, 512, 1024, 2048和4096,发送数据长度超过MTU将被分片。以write 3072字节数据为例,网卡mtu为1024,报文被分成如下三种。
- write first报文包含BTH和RETH头,其中RETH指定了远端地址和key
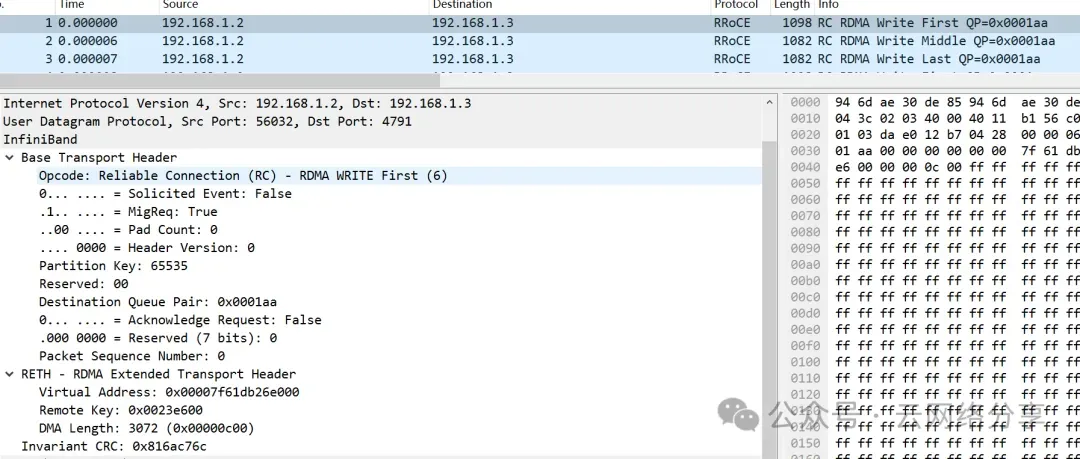
- write middle报文只包含BTH头
- write last报文只包含BTH头,并且BTH的reqack设置为1,接收端只会对此报文响应ack
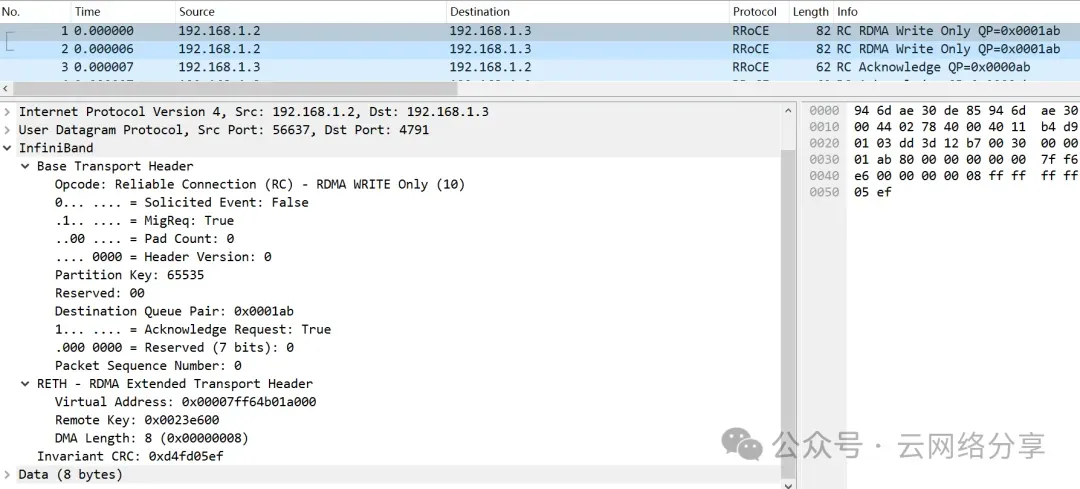
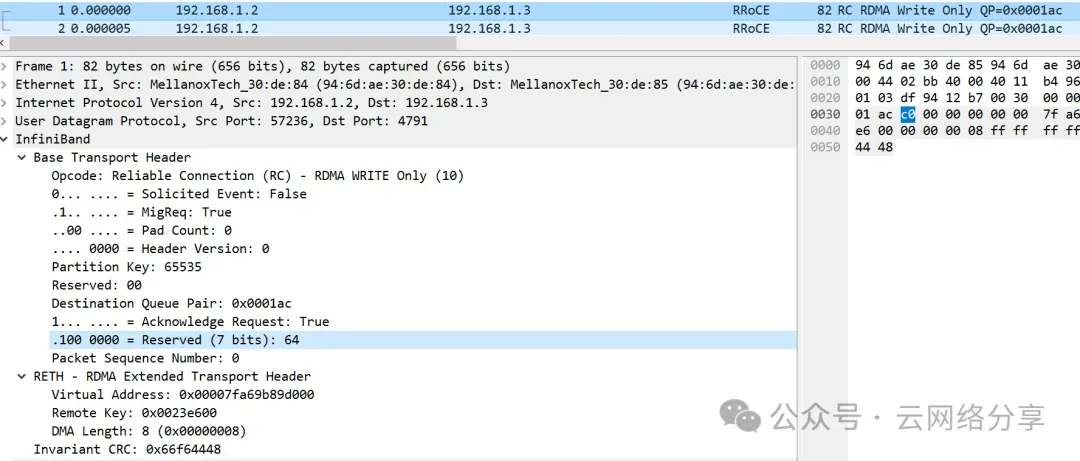
如果数据长度小于MTU则不分片,报文类型为write only,每个报文包含BTH和RETH头,其中BTH的reqack为1,RETH指定远端地址和key
自适应路由AR
打开AR功能
mlxreg -d 01:00.1 --reg_name ROCE_ACCL --set adaptive_routing_forced_en=1查看AR状态
# mlxreg -d 01:00.1 --reg_name ROCE_ACCL --get
Sending access register...
Field Name | Data
============================================================
roce_adp_retrans_field_select | 0x00000001
roce_tx_window_field_select | 0x00000001
roce_slow_restart_field_select | 0x00000001
roce_slow_restart_idle_field_select | 0x00000001
min_ack_timeout_limit_disabled_field_select | 0x00000001
adaptive_routing_forced_en_field_select | 0x00000001
selective_repeat_forced_en_field_select | 0x00000001
dc_half_handshake_en_field_select | 0x00000000
ack_dscp_force_field_select | 0x00000000
roce_adp_retrans_en | 0x00000001
roce_tx_window_en | 0x00000000
roce_slow_restart_en | 0x00000001
roce_slow_restart_idle_en | 0x00000000
min_ack_timeout_limit_disabled | 0x00000000
adaptive_routing_forced_en | 0x00000001 -->使能
selective_repeat_forced_en | 0x00000000
dc_half_handshake_en | 0x00000000
ack_dscp_force | 0x00000000
ack_dscp | 0x00000000
============================================================使能AR后,每个报文变化如下
- opcode为write only
- 包含RETH头,指定远端地址和key,让报文直接写到相应内存地址,无需做乱序重排(DDP技术实现乱序接收,按序提交)
- BTH头第9字节最高位置1,交换机可根据此标志区分ar报文
重传机制
没使能AR时,数据传输过程中,丢失其中一个分片,接收端根据报文中的PSN判断有乱序,回复NAK,指示哪个分片丢失(BTH头中的PSN),发送端收到NAK报文,重传分片及其后面所有报文。
例如网卡mtu为1024,write两次数据,每次write 3072字节数据,报文PSN为:0-5,丢失PSN1后,接收端发送NAK报文,BTH头中的PSN字段指示PSN1丢失,发送端重发PSN 1-5
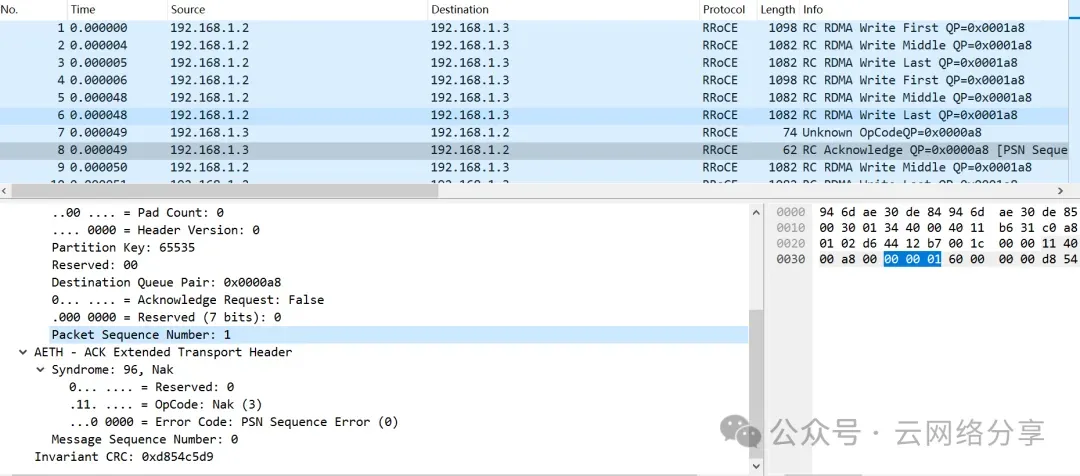
使能AR后,乱序报文是预期的,接收端维护接收窗口,接收窗口内的乱序报文超时后才回复NAK报文。
超时重传
发送数据后,接收端未响应ack,或者ack丢失,发送端会重传最新ack后的所有报文,超时时间和重传次数由如下变量指定,在调用ibv_modify_qp时设置
struct ibv_qp_attr {
uint8_t timeout;
uint8_t retry_cnt;
}timeout值和实际时间对应关系可参考 https://www.rdmamojo.com/2013/01/12/ibv_modify_qp/
0 - infinite
1 - 8.192 usec (0.000008 sec)
2 - 16.384 usec (0.000016 sec)
3 - 32.768 usec (0.000032 sec)
4 - 65.536 usec (0.000065 sec)
5 - 131.072 usec (0.000131 sec)
6 - 262.144 usec (0.000262 sec)
7 - 524.288 usec (0.000524 sec)
8 - 1048.576 usec (0.00104 sec)
9 - 2097.152 usec (0.00209 sec)
10 - 4194.304 usec (0.00419 sec)
11 - 8388.608 usec (0.00838 sec)
12 - 16777.22 usec (0.01677 sec)
13 - 33554.43 usec (0.0335 sec)
14 - 67108.86 usec (0.0671 sec)
15 - 134217.7 usec (0.134 sec)
16 - 268435.5 usec (0.268 sec)
17 - 536870.9 usec (0.536 sec)
18 - 1073742 usec (1.07 sec)
19 - 2147484 usec (2.14 sec)
20 - 4294967 usec (4.29 sec)
21 - 8589935 usec (8.58 sec)
22 - 17179869 usec (17.1 sec)
23 - 34359738 usec (34.3 sec)
24 - 68719477 usec (68.7 sec)
25 - 137000000 usec (137 sec)
26 - 275000000 usec (275 sec)
27 - 550000000 usec (550 sec)
28 - 1100000000 usec (1100 sec)
29 - 2200000000 usec (2200 sec)
30 - 4400000000 usec (4400 sec)
31 - 8800000000 usec (8800 sec)参考
RDMA杂谈:https://zhuanlan.zhihu.com/p/164908617
IB规范: https://www.afs.enea.it/asantoro/V1r1_2_1.Release_12062007.pdf